
이번 포스팅에서는 파이썬으로 삼성전자 캔들차트 만드는 방법을 정리하고자 한다.
캔들 차트 만드는 방법 중 엠피엘파이낸스(mplfinance) 패키지를 사용한 방법을 정리했다. 엠피엘파이낸스의 가장 큰 장점은 OHLC 데이터 칼럼과 날짜시간 인덱스(DatetimeIndex)를 포함한 데이터프레임만 있으면 기존에 사용자들이 수동으로 처리햇던 데이터 변환 작업을 모두 자동화 해준다는 점이다.
엠피엘파이낸스는 맷플롯립(matplotlib)과 팬더스(pandas) 라이브러리가 필요하다. 터미널에서 아래 명령으로 엠피엘파이낸스를 설치한다.
pip install --upgrade mplfinance
삼성전자 캔들 차트 만들기
import pandas as pd
import requests
from bs4 import BeautifulSoup
import mplfinance as mpf기본적으로 위의 패키지들을 import 해준다.
url = 'https://finance.naver.com/item/sise_day.nhn?code=005930&page=1'
html = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
bs = BeautifulSoup(html, 'lxml')
pgrr = bs.find('td', class_='pgRR')url은 네이버로부터 삼성전자 시세 데이터를 가져오는 부분이다. code 뒤에 삼성전자 종목 코드가 들어있다. 만약 다른 종목의 시세 데이터를 가지고 오고 싶다면 이 코드부분을 원하는 종목의 코드로 변경해주면 된다.
requests를 이용해 해당 페이지의 html 정보를 받아온다. 2021년 1월 7일부터 네이버 금융 웹 서버는 브라우저 정보(User-agent)가 없는 웹 스크레이핑을 차단하기 때문에, requests 라이브러리르 이용해 HTTP 패킷 헤더에 브라우저 정보를 추가하여 웹 페이지를 요청해야 한다.
pip install requestsrequests 라이브러리는 위 명령어로 설치할 수 있다.
.text 는 전달받은 html을 유니코드 형태로 변형해 준다.
뷰티풀 수프(BeautifulSoup)는 html, xml 페이지로부터 데이터를 추출하는 파이썬 라이브러리이다. 웹에 링크된 페이지들을 따라 돌아다니며 웹 사이트의 데이터들을 읽어오기때문에 웹 크롤러나 웹 스크레이퍼로 불린다. 뷰티풀 수프 생성자의 첫 번째 인수로 html/xml 페이지를 넘겨주고, 두번째 인수로 페이지를 파싱할 방식을 넘겨준다.
페이지를 파싱하는 방법에는 'html.parser', 'lxml', 'lxml-xml', 'xml', 'html5lib'이 있다.
pip install beautifulsoup4뷰티풀 수프는 위 명령어로 설치할 수 있다.
뷰티풀 수프의 find_all(), find() 함수를 이용해 원하는 태그를 찾을 수 있다. find_all()은 말그대로 문서 전체를 대상으로 저건에 맞는 모든 태그를 찾는다. 따라서 하나뿐인 태그를 찾을 때는 find()함수를 사용하면 더 간편하다. 아무것도 못 찾으면 find_all() 함수는 빈 리스트를, find()함수는 None을 반환한다.
url = 'https://finance.naver.com/item/sise_day.nhn?code=005930&page=1'
html = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
bs = BeautifulSoup(html, 'lxml')
pgrr = bs.find('td', class_='pgRR')
s = str(pgrr.a['href']).split('=')
last_page = s[-1]뷰티풀 수프의 find 함수로 가장 마지막 페이지를 찾고 해당 url을 가져와 '='을 기준으로 배열로 분리해준다.
s는 아래와 같은 배열이다.
print(s)
['/item/sise_day.nhn?code', '005930&page', '680']따라서 '680'이 마지막 페이지번호 이므로 s[-1]로 해당 값을 가져올 수 있다.
이제 dataframe에 삼성전자 시세 데이터를 담아줄 차례이다.
df = pd.DataFrame()
sise_url = 'https://finance.naver.com/item/sise_day.nhn?code=005930'
for page in range(1, int(last_page)+1):
url = '{}&page={}'.format(sise_url, page)
html = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
df = df._append(pd.read_html(html, header=0)[0])위 코드로 삼성전자 시세 전체 페이지를 읽어 온다.
df = df.dropna()
df = df.iloc[0:30]
df = df.rename(columns={'날짜':'Date', '시가': 'Open', '고가': 'High', '저가': 'Low', '종가': 'Close', '거래량': 'Volume'})
df = df.sort_values(by='Date')
df.index = pd.to_datetime(df.Date)
df = df[['Open', 'High', 'Low', 'Close', 'Volume']]dropna() 함수를 이용해 값이 없는 행을 삭제해줄 수 있다.
iloc[0:30]으로 삼성전자 데이터 중 30행만 슬라이싱한다.
rename() 함수를 이용해 한글 칼럼명을 영문 칼럼명으로 바꾸어 주었다.
데이터가 기본적으로 내림차순으로 되어있어 sort_values(by='Date') 함수로 날짜를 기준으로 오름차순으로 변경한다.
Date칼럼을 DatetimeIndex형으로 변경한 후 인덱스로 설정한다.
데이터에서 시가, 고가, 저가, 종가, 거래량 칼럼만 갖도록 데이터 프레임 구조를 변경했다.
Open High Low Close Volume
Date
2023-06-29 73100.0 73400.0 72400.0 72400.0 12229967.0
2023-06-30 72500.0 72700.0 71700.0 72200.0 11694765.0
2023-07-03 72700.0 73200.0 72600.0 73000.0 10722181.0
2023-07-04 73400.0 73600.0 72900.0 73000.0 10214350.0
2023-07-05 73000.0 73300.0 71900.0 72000.0 12310610.0
2023-07-06 71900.0 72400.0 71500.0 71600.0 14777667.0
2023-07-07 71100.0 71400.0 69800.0 69900.0 17308877.0
2023-07-10 70000.0 70400.0 69200.0 69500.0 11713926.0
2023-07-11 70200.0 71500.0 70100.0 71500.0 12177392.0
2023-07-12 71200.0 72000.0 71100.0 71900.0 10375581.0
2023-07-13 72400.0 72600.0 71900.0 71900.0 14417279.0
2023-07-14 72500.0 73400.0 72400.0 73400.0 15882519.0
2023-07-17 73200.0 73500.0 72800.0 73300.0 10060049.0
2023-07-18 73200.0 73500.0 72000.0 72000.0 11697900.0
2023-07-19 72700.0 72800.0 71300.0 71700.0 10896412.0
2023-07-20 71100.0 71500.0 70800.0 71000.0 9732730.0
2023-07-21 70400.0 70400.0 69400.0 70300.0 16528926.0
2023-07-24 70100.0 70900.0 69900.0 70400.0 13418597.0
2023-07-25 70000.0 70500.0 69800.0 70000.0 14314945.0
2023-07-26 69800.0 70600.0 68100.0 69800.0 29807744.0위의 코드들로 정리한 삼성전자 시세 데이터이다.
mpf.plot(df, title='Samsung candle chart', type='candle')마지막으로 제목은 'Samsung candle chart'이고 타입이 캔들 차트인 차트를 그려준다.
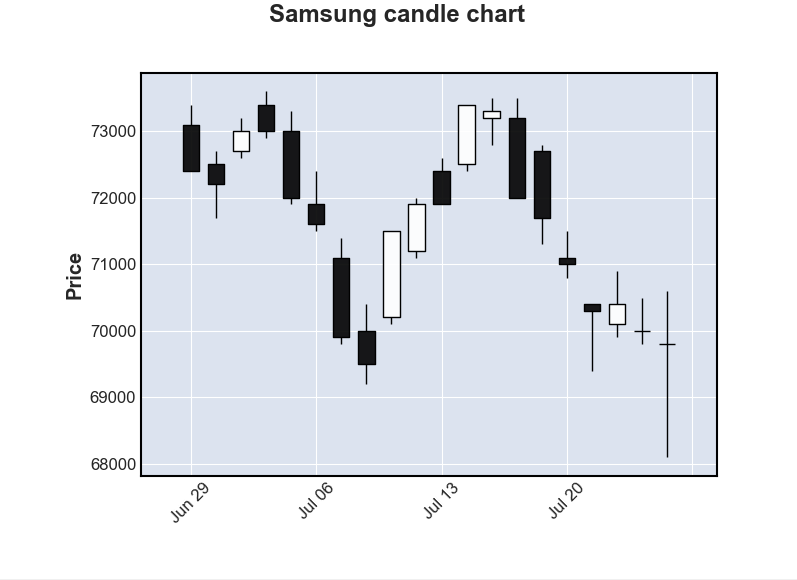
전체 코드는 아래와 같다
import pandas as pd
import requests
from bs4 import BeautifulSoup
import mplfinance as mpf
# 마지막 페이지 번호 가져오기
url = 'https://finance.naver.com/item/sise_day.nhn?code=005930&page=1'
html = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
bs = BeautifulSoup(html, 'lxml')
pgrr = bs.find('td', class_='pgRR')
s = str(pgrr.a['href']).split('=')
last_page = s[-1]
# 전체 페이지 가져오기
df = pd.DataFrame()
sise_url = 'https://finance.naver.com/item/sise_day.nhn?code=005930'
for page in range(1, int(last_page)+1):
url = '{}&page={}'.format(sise_url, page)
html = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
df = df._append(pd.read_html(html, header=0)[0])
# 데이터 프레임 가공하기
df = df.dropna()
df = df.iloc[0:30]
df = df.rename(columns={'날짜':'Date', '시가': 'Open', '고가': 'High', '저가': 'Low', '종가': 'Close', '거래량': 'Volume'})
df = df.sort_values(by='Date')
df.index = pd.to_datetime(df.Date)
df = df[['Open', 'High', 'Low', 'Close', 'Volume']]
# 캔들 차트 출력
mpf.plot(df, title='Samsung candle chart', type='candle')
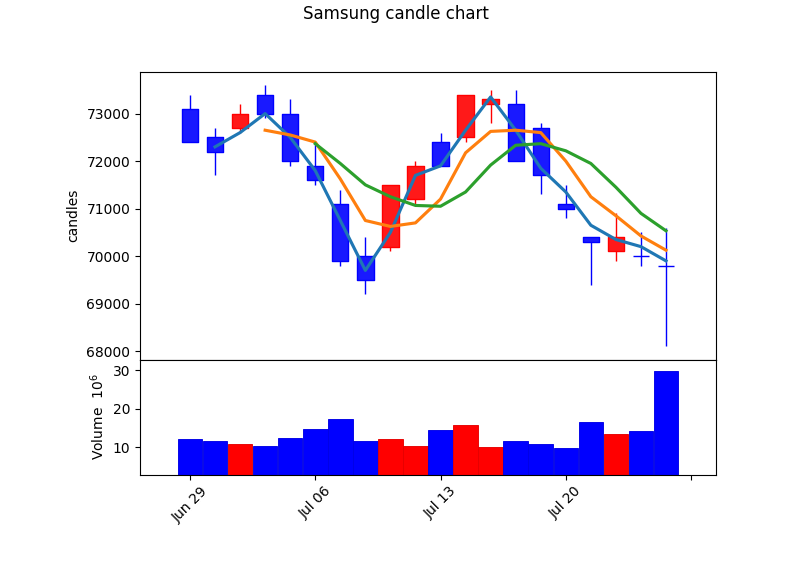
캔들 차트 변경 : 색상 변경, 거래량 차트 추가, 이동평균선 추가
kwargs = dict(title='Samsung candle chart', type='candle', mav=(2, 4, 6), volume=True, ylabel='candles')
mc = mpf.make_marketcolors(up='r', down='b', inherit=True)
s = mpf.make_mpf_style(marketcolors=mc)
mpf.plot(df, **kwargs, style=s)kwargs(keyword arguments)는 mpf.plot() 함수를 호출할 때 쓰이는 여러 인수를 담는 딕셔너리이다.
make_marketcolors() 함수로 색상을 변경할 수 있다. 'r'은 레드, 'b'는 블루를 가리킨다.
make_mpf_style() 함수의 인수로 마켓 색상을 넘겨줘 스타일 객체를 생성한다.
마지막으로 삼성전자 시세 데이터, kwargs로 설정한 인수들과 스타일 객체를 인수로 넘겨주면서 plot를 호출하여 차트를 출력한다.
엠피엘파이낸스 개발자 깃허브
https://github.com/matplotlib/mplfinance
GitHub - matplotlib/mplfinance: Financial Markets Data Visualization using Matplotlib
Financial Markets Data Visualization using Matplotlib - GitHub - matplotlib/mplfinance: Financial Markets Data Visualization using Matplotlib
github.com
참고 문헌
파이썬 증권데이터 분석 - 김황후 저
'Python' 카테고리의 다른 글
| [파이썬 증권데이터 분석] 팬더스로 상장법인 목록읽기 (0) | 2023.07.26 |
|---|

댓글